We are excited to announce the public availability of ARCH (Archives Research Compute Hub), a new research and education service that helps users easily build, access, and analyze digital collections computationally at scale. ARCH represents a combination of the Internet Archive’s experience supporting computational research for more than a decade by providing large-scale data to researchers and dataset-oriented service integrations like ARS (Archive-it Research Services) and a collaboration with the Archives Unleashed project of the University of Waterloo and York University. Development of ARCH was generously supported by the Mellon Foundation.
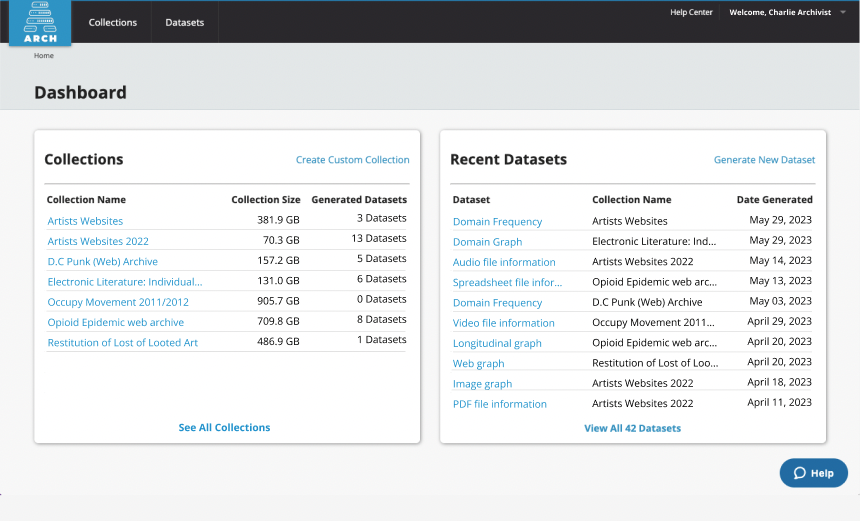
ARCH Dashboard
What does ARCH do?
ARCH helps users easily conduct and support computational research with digital collections at scale – e.g., text and data mining, data science, digital scholarship, machine learning, and more. Users can build custom research collections relevant to a wide range of subjects, generate and access research-ready datasets from collections, and analyze those datasets. In line with best practices in reproducibility, ARCH supports open publication and preservation of user-generated datasets. ARCH is currently optimized for working with tens of thousands of web archive collections, covering a broad range of subjects, events, and timeframes, and the platform is actively expanding to include digitized text and image collections. ARCH also works with various portions of the overall Wayback Machine global web archive totaling 50+ PB going back to 1996, representing an extensive archive of contemporary history and communication.
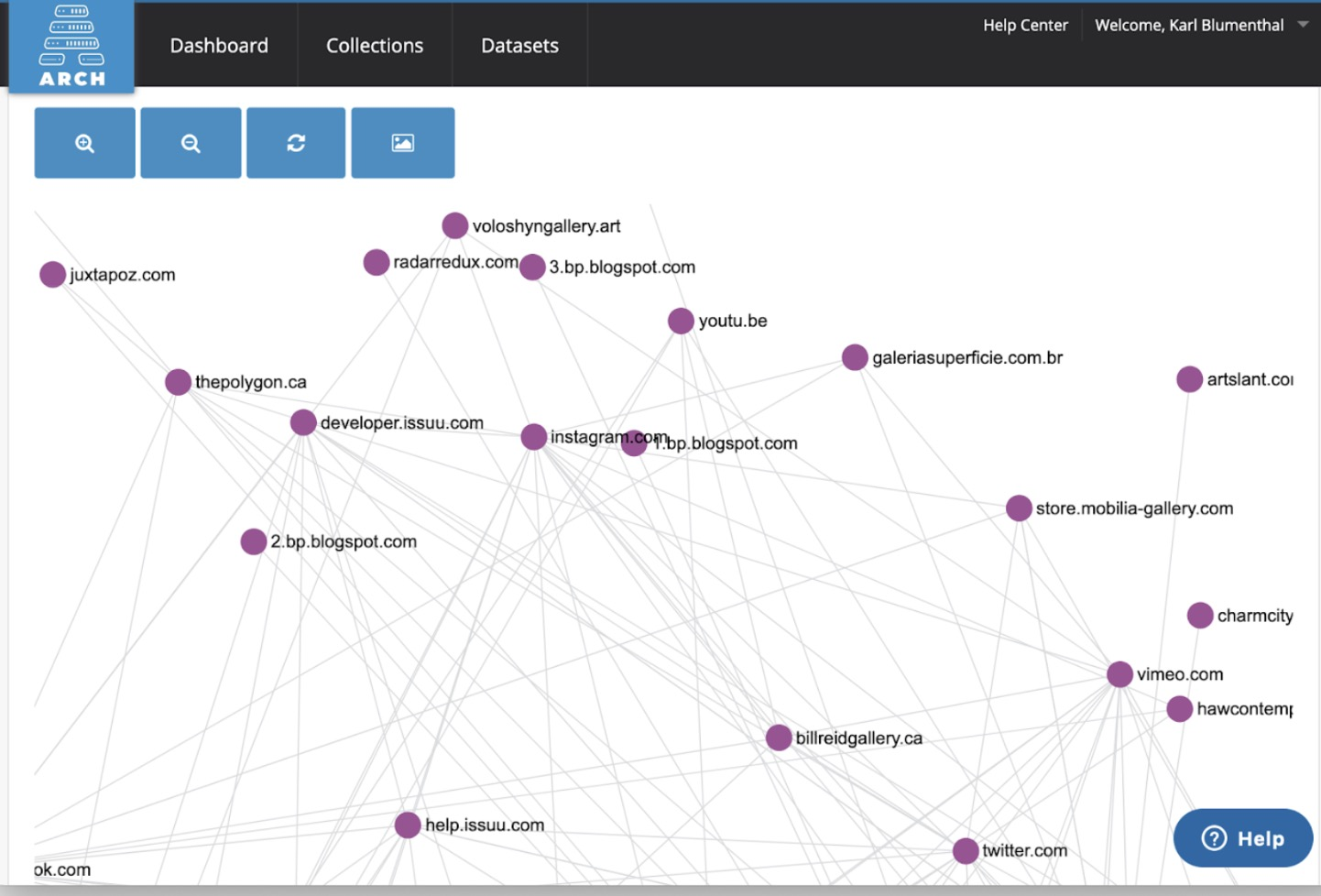
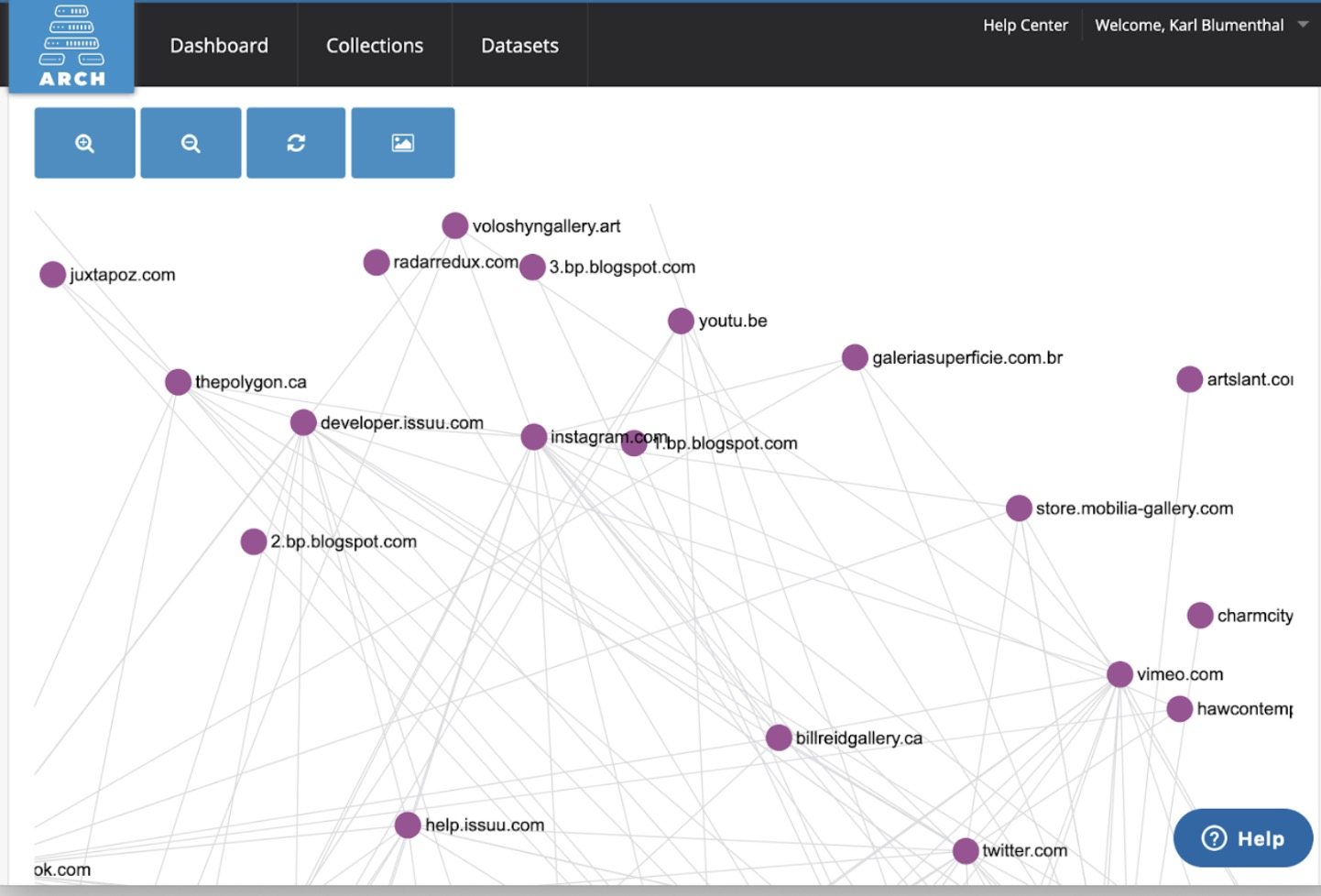
ARCH, In-Browser Visualization
Who is ARCH for?
ARCH is for any user that seeks an accessible approach to working with digital collections computationally at scale. Possible users include but are not limited to researchers exploring disciplinary questions, educators seeking to foster computational methods in the classroom, journalists tracking changes in web-based communication over time, to librarians and archivists seeking to support the development of computational literacies across disciplines. Recent research efforts making use of ARCH include but are not limited to analysis of COVID-19 crisis communications, health misinformation, Latin American women’s rights movements, and post-conflict societies during reconciliation.

ARCH, Generate Datasets
What are core ARCH features?
Build: Leverage ARCH capabilities to build custom research collections that are well scoped for specific research and education purposes.
Access: Generate more than a dozen different research-ready datasets (e.g., full text, images, pdfs, graph data, and more) from digital collections with the click of a button. Download generated datasets directly in-browser or via API.
Analyze: Easily work with research-ready datasets in interactive computational environments and applications like Jupyter Notebooks, Google CoLab, Gephi, and Voyant and produce in-browser visualizations.
Publish and Preserve: Openly publish datasets in line with best practices in reproducible research. All published datasets will be preserved in perpetuity.
Support: Make use of synchronous and asynchronous technical support, online trainings, and extensive help center documentation.
How can I learn more about ARCH?
To learn more about ARCH please reach out via the following form.